학부 시절 부동소수점이라고 소수를 컴퓨터에서 이렇게 표현한다~라고 거의 심적으로는 철학자의 한 명언처럼 머리 어느 한 구석에 어렴풋이 흔적만 남아있었는데, 실제 실무에서 이 부동소수점의 근사치 오차 때문에 경곗값을 이탈하며 크래쉬가 난 것을 경험하고 말았다.
이게 뭔, 거의 죽었다고 생각했던 3화에 퇴장한 엑스트라가 26화에서 흑막으로 나타난 상황이냐
정신을 번쩍 차리고 뇌 속에 있는 흔적을 더듬어 다시 정리해 보기로 했다.
부동소수점(floating point)이란?
컴퓨터에서 실수(예시: float, double)를 유한한 bit를 통해 표현하는 방식 중 하나.
소수점 위치를 고정하지 않고 지수와 가수를 사용하여 매우 큰 수나 작은 수를 근삿값으로 표현한다.
컴퓨터는 숫자를 bit로 표현한다. 예를 들어 38은 2진수로 100110으로 표현되며, 이는 전압(전기가 통할 때 1, 전기가 통하지 않을 때 0)을 통해 6개의 bit로 표현할 수 있게 된다.
또한, 8bit는 1 Byte로 흔히 정수로 사용되는 Int는 JVM에서 4 Byte 메모리를 사용한다.
즉, 0000 00000 X 4 이렇게 32bit로 숫자를 표현하는 것이다.
컴퓨터 OS에서 설치 파일을 고를 때 가끔 window에서 32bit 운영 체제와 64bit 운영 체제를 골라야 할 때가 있는데,
이는 데이터 작업 단위 크기가 32bit인 것과 64bit인 것이다.
x86 프로세스도 인텔의 32bit ...
다시 돌아와서,
그렇다면 38과 같이 정수가 아닌 12.1082 같은 실수는 어떻게 표현될까?
12.125를 2진법으로 바꾸면 다음과 같다.
1100.001 이렇게 할 때, 정수 부분과 소수 부분을 나눈다면, 1100/001 이렇게 표현할 수 있을 것이다.
이를 소수점이 고정되었다고 하여 고정소수점(fixed pint)이라고 한다.
그러면 고정 소수점 표현을 살짝 살펴보자.
만약 16bit(32bit는 쓰기에는 너무 많으니까..)를 사용한다면 다음과 같을 것이다.
첫자리는 부호 비트로 사용한다. (+/-)
그리고 앞 비트 묶음을 정수를 표현, 뒷 비트 묶음을 소수를 표현한다.
bit 구분: 0 / 000 0000 / 0000 0000
12.125 표현: 0 / 000 1100 / 0010 0000

자 그러면 이제 부동 소수점으로 표현할 경우를 알아보자.
고정 소수점과 달리 부동 소수점 표현은 어떻게 표현되는 걸까.
우선 부동 소수점은 실수를 고정 소수점보다 한정된 자원(정해진 bit 크기)으로 좀 더 효율적으로 표현하기 위해서 사용한다. 이게 무슨 말이냐면, 아까 말한 비트 묶음을 다시 살펴보도록 하자.
0 / 000 1100 / 0010 0000
이렇게 사용할 경우 처음 부호비트를 제외하고 15bit를 반으로 나눠 하나는 정수, 하나는 소수로 사용하게 된다.
그럴 경우 정수부의 숫자도 겨우 bit 7개로 밖에 표현하지 못해 표현(2⁷ = 128 가지)할 수 있는 숫자 범위도 작고 (고작, -64 ~ 63),
소수부 표현의 정밀도가 떨어진다. bit를 낭비하게 되는 것이다.
그렇다면 좀 더 효율적으로 표현하기 위해 어떤 방식을 취할 수 있을까
바로 소수점을 옮겨서 저장하는 것이다.
12.125의 수를 2진수로 바꾼 1100.001의 소수점을 맨 앞으로 옮긴다.
그러면, 1.100001이 된다. 그리고 이 값과 이전 값과 동일하게 하기 위해서 2³를 곱해야 할 것이다.
1100.001 = 1.10001 x 2³
그리고 여기서 소수점 아래의 .10001을 가수부(Mantissa)라고 하며, 이렇게 표현할 경우 가수부를 제외한 지수부는 무조건 1이 오게 되는 것이다. 지수부는 무조건 1로 고정되니 의미 없는 숫자이며, 우리는 가수부와 얼마큼 소수점을 옮겼는지(2³)를 지수부라고 하며,
부호부, 지수부, 가수부 이렇게 분리해서 bit로 표현할 수 있다.
그렇게 되면 만약 동일한 bit를 사용할 때, 고정소수점 방식과 달리 부동소수점 방식은 수의 어느 범위까지 표현할 수 있을까?
자, 그러면 일단 아까와 동일하게 16bit를 사용하여 12.125를 표현해 보도록 하자.
여기서 잠깐 아까 소수점을 옮기면서 지수부라는 소수점 위치를 표시해 주는 데이터가 생겼는데,
해당 지수 값은 +/-가 될 수 있을 것이다. 그렇지만 따로 지수에 대한 연산과 낭비를 피하기 위해 부호 비트는 표현하지 않으며, 부동소수점에는 이를 보완하기 위해 Bias라는 오프셋 값이 존재한다.
IEEE 754 기준 16bit 기준으로는 이 값은 15를 사용한다. (16bit에서 지수부가 이것보다 작을 수 없기 때문)
Bias(바이어스)
지수(exponent)를 음수·양수 모두 표현하기 위해 더해주는 고정 오프셋 값
bit를 다음과 같이 나눌 때 지수부는 15+3 = 18로, 18이란 숫자로 표현해 주면 되는 것이다.
다음과 같이 표현 가능하다.
bit 구분: 0 / 000 00 / 00 0000 0000
12.125 표현: 0 / 100 10 / 10 0001 0000

아까 전, 고정소수점을 사용할 때 16bit를 사용하여 수를 표현하면 고작 64 ~ 63 범위 밖에 표현하지 못하였다.
그러면 위의 16bit의 부동소수점을 기법을 사용하면 다음과 같이 표현이 가능하게 된다.
- 최대 유한 양수 ≈ +65504
- 최소 유한 음수 ≈ -65504
- 가장 작은 양수 (정규화) = 2⁻¹⁴ ≈ 0.00006103515625
- 가장 작은 양수 (비정규화) = 2⁻²⁴ ≈ 0.0000000596046448
즉, -65504 ~ +65504 범위를 표현 가능하게 되는 것이다.
유연한 소수점 위치를 통해 정수와 소수부의 크기나 정밀도를 타협하여 좀 더 유연한 수 범위를 표현할 수 있게 되는 것이다.
그렇기 때문에 대부분의 컴퓨터는 실수를 표현할 때, 부동소수점 기법을 사용한다.
일반적으로 부동소수점은 IEEE 754 표준 기법을 따른다.
부동소수점의 핵심 구성 (IEEE 754 표준)
- 부호부 (Sign, 1 bit): 양수(0) 또는 음수(1)를 결정.
- 지수부 (Exponent): 소수점의 위치를 나타내어 표현할 수 있는 수의 범위를 결정.
- 가수부 (Mantissa/Significand): 실제 유효 숫자를 표현.

자, 우리는 이제 컴퓨터가 실수를 표현하는 방법에 대해 알게 되었다.
그렇다면 우리는 알아야 한다.
컴퓨터는 유한한 bit로 실수를 표현하는 것이다.
사실 실수는 유한하지 않다. 심지어 10진수를 2진수로 표현한다면.. 숫자의 범위뿐만 아니라 소수의 정밀도에서도 타협을 봐야 한다.
10진수를 2진수로 변환할 때 발생하는 무한 소수 문제로 인해 오차(근삿값)가 발생할 수 있다는 것인데, 구체적인 예시를 통해 살펴보자.
예를 들어 다음과 같은 소수를 보자.
0.1
이 숫자를 2진수로 바꾸면 다음과 같다.
0.0001100110011001100110011...
또 다음 10진수 숫자를 2진수로 바꿔 보자,
0.3₁₀ -> 0.0100110011001100110011...₂
이렇게 10진수의 소수를 2진수로 변경할 때 딱 떨어지지 않고 무한히 반복되는 경우가 종종 있다.
하지만 컴퓨터는 유한한 bit로 숫자를 표현해야 하기 때문에 일부 값을 누락시켜야 한다.
0.0001100110011001100110011... -> 0.0001100110 / 011001100110011...
0.0100110011001100110011... -> 0.0100110011 / 001100110011...
자 이렇게 bit에 유한한 값을 저장해 두고 이제 값을 사용할 때 컴퓨터는 다시 10진법으로 계산하게 된다.
0.0001100110₂ -> 0.099609375₁₀
0.0100110011₂ -> 0.2998046875₁₀
이럴 수가. 각각 0.1, 0.3의 숫자가 아닌 다른 값이 나왔다.
즉, 실제 컴퓨터는 소수에 대해 0.1이 아닌 0.099609375라는 0.1의 근삿값과 0.3이 아닌 0.2998046875라는 근삿값으로 사용하는 것이다.
이리고 이 것은 숫자를 2진수로 관리하는 컴퓨터가 가지고 있는 오차값이고, 이것은 우리 개발자가 인지하고 있어야 하는 부분이다...
그렇지 않으면 이런 일을 겪게 된다.
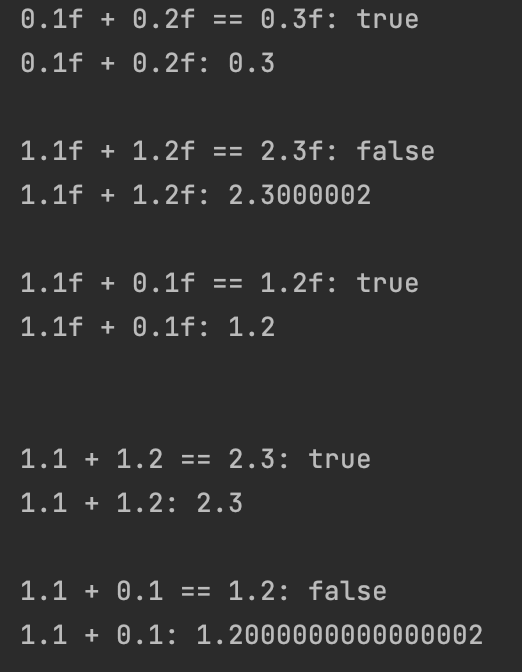
이런 결과에서 "ㅋㅋ 신기하네" 하고 지나가는 것이 아니라
진짜 운영에서 이런 일이 일어나는 것이다. (심지어 OS, 컴퓨터 상태에 따라 결과가 달라질 수도 있다..)

확인해 보니 애니메이션에서 디자인 lottie 리소스 문제로 가장 처음 프래임과 가장 마지막 프레임을 프로그래밍 적으로 누락시키면서 0.01 - 0.99라는 프래임을 무한 반복하고 있었는데, 이 실수에 * % + - 하면서 오차 값이 겹겹이 쌓이게 되면서 결국 좌표계 범위를 넘어가게 된 것으로 보였다...
하여튼, 이 오차 범위가 소수의 정밀도라는 것인데 컴퓨터에서 소수를 표현할 때 사용하는 bit의 수가 많아질수록 이 정밀도가 높아지는 것이다. (심지어 오차 범위도 숫자에 따라 달라짐..)
흔히 float 형식에 사용되는 bit 수는 32bit이고 double형은 64bit로, double 형이 좀 더 정밀하게 수를 표현할 수 있다.
(물론 그만큼 2배의 데이터 공간을 사용하게 된다.)
즉, 쉽게 보면 float(32bit)의 오차 범위는 ≈ 5.96×10⁻⁸, double(64bit) 형의 오차 범위는 ≈ 1.11×10⁻¹⁶ 정도 된다.
이렇게 소수는 값 자체가 컴퓨터에서 참값이 아닌 근삿값으로 표현될 수 있게 되는데,
그렇기 때문에 금융같이 소수점 수에 민감한 데이터(환율, 이자 등) 일 경우 다른 방식으로 수를 저장해야 한다.
보통 이때 사용하는 것이 BigDecimal인데,
이것은 2진 근삿값을 저장하는 방식이 아닌 10진수 값을 그대로 저장하고 계산하는 숫자 타입니다.
물론 그만큼 금융이 아닌 수치 계산이나 좌표계 등에서는 분리하게 속도도 느리고 메모리도 크게 잡는 데이터 저장 방식이다.
일반적인 상황에서는 float 형식으로 웬만한 계산 하지 하지 않는 게 정신건강에 좋다. 1000을 곱해서 정수로 관리하든, 반올림이나 버리을 해서 소수를 다 날려버리든.. double로 유예기간을 늘리든..
실제 부동소수점을 사용하는 애니메이션 관련 Android 라이브러리에서는 해당 문제를 개선한 commit도 이렇게 존재한다.

관련 commit diff 페이지
수정된 Android 라이브러리: Compose Animation 버전 1.8.0-alpha04
못다 한 이야기
- IEEE 754 표준 이외
- BigDecimal 동작 방식
- BigDecimal vs Double
'Android > 학습' 카테고리의 다른 글
| [Android] Android 16 (target SDK 36) 대응 (0) | 2026.03.14 |
|---|---|
| [Android] targetSdk와 compileSdk의 차이, 그에 따른 영향. (0) | 2026.02.22 |
| [kotlin] by로 보는 지연 초기화 by lazy 컴파일러 동작 방식 (0) | 2026.01.10 |
| [Firebase] Remote Config, 어떻게 사용하고 왜 사용하는가? (0) | 2025.11.29 |
| [Android] Kotlin Flow의 first (with. Cold Steam, Hot Steam) (0) | 2025.11.09 |