Room은 안드로이드 로컬 데이터베이스 서비스를 제공하는 AAC(Android Architecture Components)이며,
SQLite의 추상화 계층을 제공한다.
그렇기 때문이 SQLite에서 사용할 수 있는 INDEX도 Room에서 사용할 수 있다.
학부 시절에 배운 내용을 더듬어 해당 내용을 복습하고자 한다.
INDEX를 사용하면 쿼리를 빠르게 실행할 수 있다.
그럼 INDEX는 어떤 원리로 쿼리를 빠르게 실행할 수 있는 걸까?
DB의 데이터들은 순서가 보장되지 않는 데이터들이다.
그렇기 때문에 특정 데이터를 찾기 위해서는 데이터 전체를 훑어보는 과정(Full-Table-Scane)을 거치게 된다.
예를 들어 다음과 같은 쿼리가 실행되면, DB는 다음과 같은 과정을 거친다.
SELECT * FROM 고객 WHERE 나이 = 21
- '고객' 테이블의 모든 row를 처음부터 끝까지 탐색한다.
- 각 row의 '나이' 값을 읽어서, 21과 같은지 비교한다.
- 조건에 맞는 row를 결과 리스트에 추가한다.
이 과정은 데이터가 많을수록 O(n) 시간이 걸린다. 즉, 100만 개의 row가 있으면 100만 번 비교하는 셈인 것이다.
INDEX
DB에서 특정 칼럼에 Index를 설정하면, 내부적으로 index로 설정된 칼럼을 복사하여 정렬해 둔다.
즉, 다음과 같은 Table이 있다고 할 때, [나이] 칼럼을 Index로 설정한다면,
| ID | 이름 | 나이 | 주소 |
| 1 | 김 | 28 | 서울 |
| 2 | 이 | 18 | 부산 |
| 3 | 박 | 23 | 대구 |
| 4 | 최 | 21 | 대전 |
| 5 | 정 | 25 | 울산 |
| 6 | 강 | 31 | 인천 |
| 7 | 조 | 19 | 광주 |
다음과 같은 정렬된 컬럼 복사본이 존재하게 되는 것이다.
| 나이 |
| 18 |
| 19 |
| 21 |
| 23 |
| 25 |
| 28 |
| 31 |
알고리즘을 배운 입장에서 이렇게 정렬된 데이터에 대한 탐색은 매우 빠르게 진행(O(N) -> O(logN))될 수 있음을 우리는 알고 있다.
그렇기 때문에 INDEX를 설정함으로써 우리는 해당 칼럼에 대한 검색 쿼리를 빠르게 실행할 수 있게 되는 것이다.
참고 자료: 이진 탐색 알고리즘
List 형식은 메모리에 저장되는 형식에 따라 Array나 Linkedd List 등으로 관리될 수 있고, 이 방식에 따라 쿼리 성능이 차이가 날 것이다.
그렇다면 DB의 INDEX는 어떤 식으로 저장될까?
사실 실제 INDEX는 저렇게 리스트 형식으로 저장되는 것은 아니다.
그러면 어떤 식으로 저장되느냐? 그것은 Tree 형태이다.

List 형식보다 더 빠르게 접근이 가능한 구조를 취한 것이다. (이진 탐색에 매우 적합, Binary Search Tree)
또한, 흩뿌려진 데이터들을 일일이 정리해서 줄 세워두는 것이 아닌 연결(주소값)만 해두는 것이다.
그냥 봐도, 개념적으로 리스트보다 우수한 성능을 이끌어낼 것 같다.
하지만 여기서, DB는 쿼리 성능을 더 강화시키기 위해 더 개선된 자료구조를 사용한다.
B-Tree
이진 Tree 형태에서 하나의 node에서 하나 이상의 데이터들을 가지거나 두 개 이상의 자식들을 가지는 Tree이다.

약간 이런 식으로 생긴 Tree인데, 데이터 수를 늘려서 본다면 다음과 같다.

이렇게 한다면, 이진트리처럼 절반을 나눠 검색하는 것이 아닌 더 효율적인 검색이 가능하다. (1/3, 1/4...)
DB에서 이렇게 B-Tree 형색의 자료구조를 사용하여 INDEX를 구성하는 경우가 많았다.
물론 요즘은 더 향상된 구조를 사용하는 DB들도 있는데, B+Tree에 대해서 살펴보자.
B+Tree
B-tree를 개선한 구조로, 모든 실제 데이터는 리프 노드에만 저장되고, 리프 노드끼리 연결(Linked List)된 자료구조이다.
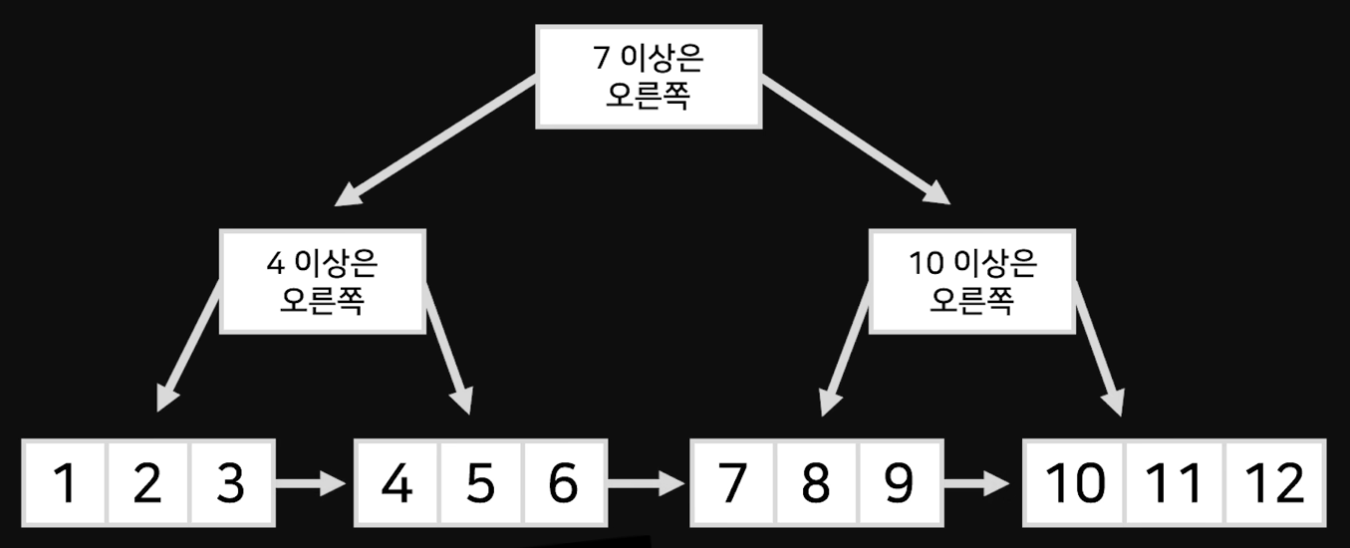
해당 구조 덕분에 B+Tree는 범위 검색(Range Scan)에 최적화되어 있다.
리프 노드가 Linked List처럼 연결되어 있어 “이상 ~ 이하” 같은 연속된 조건 검색이 빠른 것이다.
이렇게 INDEX를 사용하면 해당 칼럼에 해당하는 일치, 범위 검색이나 정렬, 필터링 연산에 매우 유리하게 동작할 수 있게 되는 것이다.
트레이드오프(Trade-Off), 부작용
INDEX의 장점과 원리를 확실히 아니 Trade-Off에 대해서도 쉽게 이해할 수 있다.
쿼리 속도를 빠르게 하기 위해 DB가 INDEX라는 정렬된 칼럼 복사본을 가지고 있는 개념이기 때문에 다음과 같은 부분을 고려해야 한다.
- 저장 공간
- INDEX 생성 공간
- 쓰기(Write) 성능 저하
- 삽입, 수정, 삭제 시 INDEX 반영 비용
그렇기 때문에, 자주 사용되는 쿼리를 분석하여 효율적인 INDEX를 만들어 두는 것이 중요하다.
참고로, Primary Key에 대해서는 기본적으로 INDEX가 생성된다.
Room에서 Index 설정
room에서는 다음과 같이 엔티티에 Index를 명시하여 설정할 수 있다.
해당 Index는 복합 인덱스이다.
@Entity(indices = [Index(value = ["last_name", "address"])])
추가적으로 알아보면 좋을 것
- HashMap, HashTable
- 복합 인덱스 차이와 이점
참고 자료
'Android > 학습' 카테고리의 다른 글
| [Android] Kotlin Flow의 first (with. Cold Steam, Hot Steam) (0) | 2025.11.09 |
|---|---|
| [Android] 딥링크(deeplink) - App Link (0) | 2025.10.12 |
| [Git] GitFlow(깃플로우), 기존 Git 명령어 관점에서 (3) | 2025.08.23 |
| [Git] Git Merge 종류 (with. force push로 commit이 사라졌을 경우) (8) | 2025.08.09 |
| [Android] LiveData란 (vs StateFlow) (6) | 2025.07.19 |